Features
Login
Currently, all the analyst has to do is navigate to the instance (IP address and port). Future revisions may require a username/password combination.
Ingest Process
Before an investigation can start, the dataset(s) need to be ingested. Newman can ingest multiple pst, mbox, and eml datasets. There are two methods to ingest a dataset; UI and command line. Both methods require that the datasets be placed in a specific location before the ingester will work.
User Interface
To use the UI, three nested directories need to be created for each dataset.
- The top level must be the case name and is user definable. [no spaces]
- The second level is the eml archive type and must be one of [pst, mbox, emls]
- The third level is the data_set label (which will appear in the UI) and is user definable [no spaces]
- Under that dir you can put any data files or directories you have and they will be ingested
Below are some example steps (end-to-end) to ingest a pst file on an existing VirtualBox (see Quick Start Guide for steps to setup a VirtualBox with Newman).
- Open a cmd terminal. On Windows, select Start icon, type in cmd, and select cmd.exe.
- SSH into the VirtualBox, C:\Users\jsmith\virtualboxvms\Newman\vagrant ssh
- Create the 3 nested directories and then copy the dataset. May have to create newman-ingester directory if it does not exist.
vagrant@vagrant-ubuntu-trusty-64:/vagrant$ mkdir newman-ingester
vagrant@vagrant-ubuntu-trusty-64:/vagrant$ cd newman-ingester/
vagrant@vagrant-ubuntu-trusty-64:/vagrant/newman-ingester$ mkdir TestPST
vagrant@vagrant-ubuntu-trusty-64:/vagrant/newman-ingester$ mkdir TestPST/pst
vagrant@vagrant-ubuntu-trusty-64:/vagrant/newman-ingester$ mkdir TestPST/pst/TestPST1
vagrant@vagrant-ubuntu-trusty-64:/vagrant/newman-ingester$ mv TestPST.pst TestPST/pst/TestPST1/
Now that the dataset is in the correct location, select Database icon and then New Dataset…

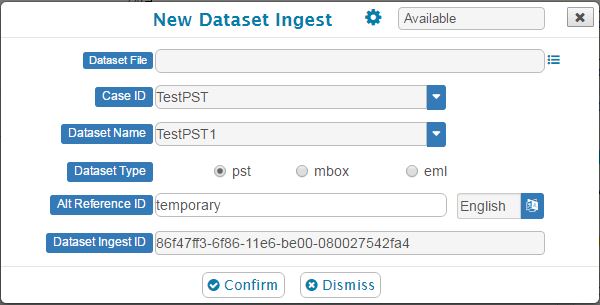
Add a Alt Reference ID if desired and then the Confirm button. A status dialog will be presented which will disappear when the ingest is completed. In the future, the status will be displayed in a Tasks tab so the user can work on other datasets while new ones are being ingested.

Command Line
Follow the steps below to use the command line to ingest datasets. Note: you may have to create this directory structure if it does not exist.
-
Copy dataset to the appropriate location.
For emls files: /srv/software/pst-extraction-master/pst-extract/emls
For mbox files: /srv/software/pst-extraction-master/pst-extract/mbox
For pst files: /srv/software/pst-extraction-master/pst-extract/pst -
Change directory to /srv/software/pst-extraction-master/
cd /srv/software/pst-extraction-master/
-
Execute the appropriate ingest command
For emls files: ./bin/eml_all.sh newman-
Note:
• ingest_id name is limited to the file system. The ingest_id must be lowercase, not start with _ . and not include any of these characters \ / * ? " < > | , .
• index-id must be unique and unused on the ES backend
• 2>&1 is optional and just redirects stderr into stdout
• | tee /tmp/file is also optional. It pipes all results to tee logging
• label shows up on the newman main page
Below is a step by step example to ingest mypst.pst.
cp mypst.pst /srv/software/pst-extraction-master/pst-extract/pst
cd /srv/software/pst-extraction-master/
./bin/pst_all.sh newman-mypst_ingest MyPST_case personal_alt_ref Mypst_label en
Search
The first step in an investigation is usually to initiate a search. By default, all datasets that have been ingested are searched. The analyst has the choice to de-select datasets to only search specific datasets.
Search Criteria

The search text box is backed by elasticsearch
and will return results for all the emails and attachments ingested. For a detailed
guide, navigate to Elastic Search Guide
This query string is parsed into a series of terms and operators. A term can be a
single word like quick or brown or a phrase, surrounded by double quotes
"quick brown" which searches for all the words in the phrase, in the same
order. Operators allow the analyst to customize the search. Operations that are
supported include field names, wildcards, fuzziness, proximity searches, ranges,
Boolean operators, and grouping. Elastic Search has a list of reserved characters
that need a leading backslash to escape them. The reserved characters are: + - = && || > < ! ( ) { } [ ]
^ " ~ * ? : \ /
Field Names
When no fields are specified, every field is by default searched. The fields available for searching depend on the dataset and how it was ingested. Most datasets based on email will include the following fields:
body | body_lang | body_translated |
subject | subject_lang | subject_translated |
senders | bccs | ccs | tos |
attachments.extension | attachments.exif.gps | attachments.content |
attachments.filesize | attachments.filename |
addrs (this is an aggregated field that includes searches senders, bccs, ccs, tos)
Example searches
subject:quick |
where subject field contains quick |
subject:quick OR brown |
where subject field contains quick or brown |
subject:quick brown |
the default operator is OR. So, where subject field contains quick or brown. |
body:”quick brown” |
where body field contains the exact phrase “quick brown” |
_missing_:subject |
where the field subject has no value |
_exists_:attachments.exif.gps |
where the field attachments.exif.gps has a value (i.e. has location) |
Note: capitalization does not matter for search terms (i.e. a search for quick Quick
or QUICK will return the same results). The operators (OR AND NOT) must be
capitalized and the field names must be all lowercase.
Wildcards
Wildcard searches can be run on individual terms, using ? to replace a single character, and * to replace zero or more characters:
jo?n john*
Be aware that wildcard queries can take longer to execute; in particular, searches with a wildcard at the beginning of a word (*ing).
Fuzziness
Search for terms that are similar to, but not exactly like our search terms. Using the “fuzzy” operator will find all terms with a maximum of two changes, where a change is the insertion, deletion or substitution of a single character or transposition of two adjacent characters. Different edit distances can be specified by including a number (~1). Using a distance of 1 is usually sufficient to catch 80% of all human misspellings.
Jon~ tomato~
Proximity searches
While a phrase query (“john smith”) expects all of the terms inexactly the same order, a proximity query allows the specified words to be further apart or in a different order. In the same way that fuzzy queries can specify a maximum edit distance for characters in a word, a proximity search allows the analyst to specify a maximum edit distance of words in a phrase.
“john smith”~5 finds John Smith, John Adams Smith, Smith, John
Ranges
Can be specified for date, numeric, or string fields. Inclusive ranges are specified with square brackets [min TO max] and exclusive ranges with curly brackets {min TO max}.
attachments.filesize:[100 TO 500] attachments.filesize:[10000 TO *] attachments.filesize:[1000 TO 5000} attachments.filesize:>10000 attachments.filesize:>=10000 attachments.filesize:<10000 attachments.filesize:<=10000
Boolean operators
By default, all terms are optional, as long as one term matches. A search for foo bar baz will find any document that contains one or more of foo or bar or baz. There are also boolean operators which can be used in the query string itself to provide more control. The preferred operators are + (this term must be present) and - (this term must not be present). All other terms are optional. For example, this query:
quick brown +fox -news
states that:
- fox must be present
- news must not be present
- quick and brown are optional — their presence increases the relevance
The familiar operators AND, OR and NOT (also written &&, || and !) are also supported. However, the effects of these operators can be more complicated than is obvious at first glance. NOT takes precedence over AND, which takes precedence over OR. While the + and - only affect the term to the right of the operator, AND and OR can affect the terms to the left and right.
Grouping
Multiple terms or clauses can be grouped together with parenthesis to form sub queries.
subject:(quick OR brown) AND body:fox
Filtering
By default, the only active filter is the Date range control. The initial dates picked are maximized to include as many emails as possible. This control also provides a bar graph of email traffic distribution.

Search Results

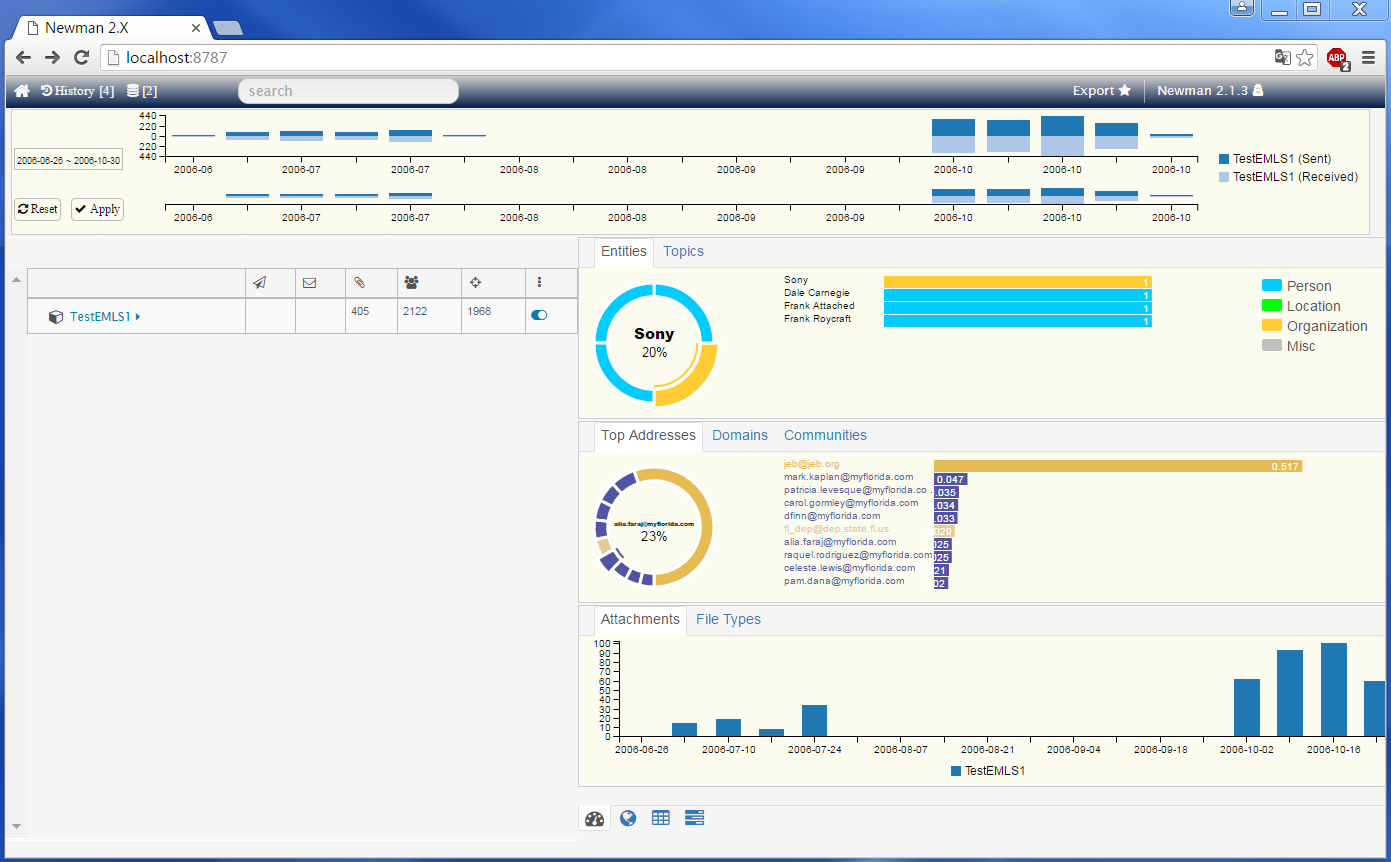
Each search updates the dashboard to include the number of accounts associated and the number of emails the search matched. Selecting the search term populates a social graph and email/attachments list.
The most relevant Accounts Ranked or Entities Extracted can be displayed in the Search Results list by selecting the arrow to the right of the dataset. The analyst can then select the number they like to view with a mazximum of 50.

If a search has been initiated as in this example, then the top Accounts Ranked displayed are those that include the search term.
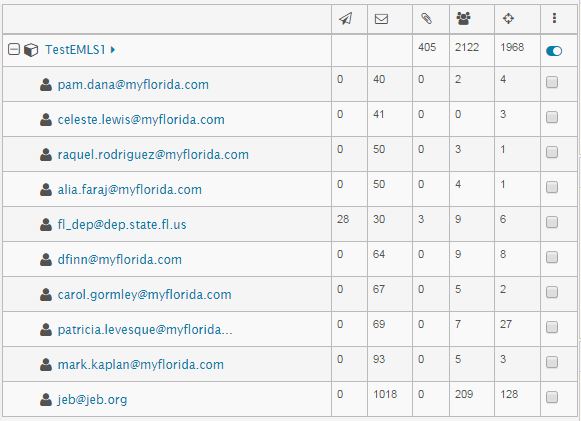
From Search Results list, the analyst can select/deselect checkboxes to filter the data sent to the analysis widgets. Selecting an email address populates a social graph and email/attachments list for that email address.
Analysis Widgets
Entities/Topics
The entities tab shows the highest occurring entities extracted by MITIE . Clicking on one of the entities will requery for emails which contain that entity.
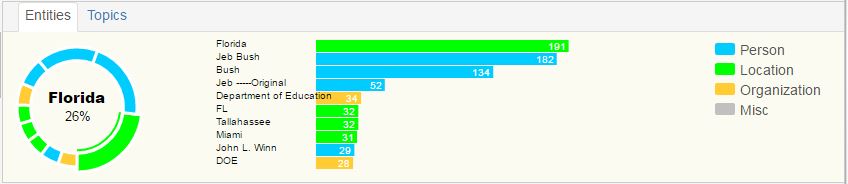
The topics tab shows the topics among all of the emails. Clicking on one of the topics will re-query for all of the emails that score greater than 75% on that topic.
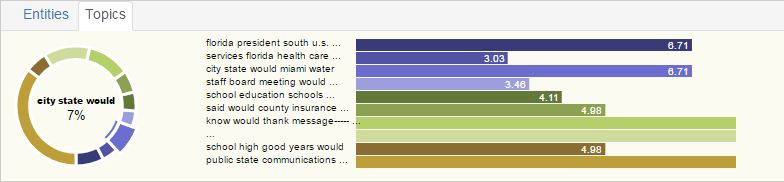
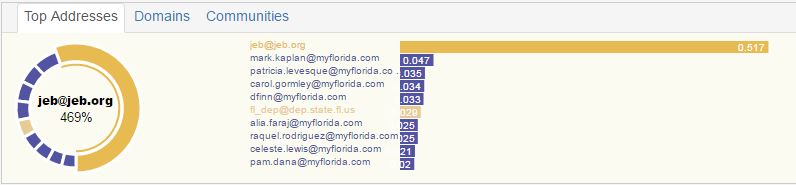
Top Addresses/Domains/Communities
Top Addresses uses a custom algorithm to determine important email addresses in the data set. Clicking on one of the email addresses will re-query for all the emails for that email address.
Domains listed are the top 10 domains of all the emails in the dataset selected.
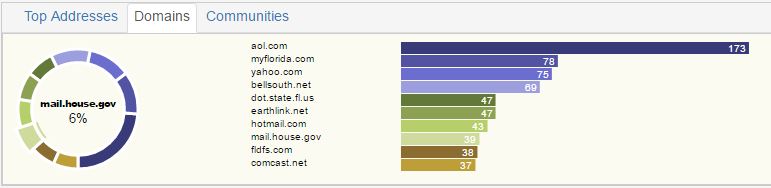
Communities listed are the top 10 communities in the dataset selected. A community is determined by an algorithm run on the server. Currently, the Community is arbitrarily named by one of the email addresses. A better name will be provided in the future with either the top topic in that community and/or number of entities in that community.
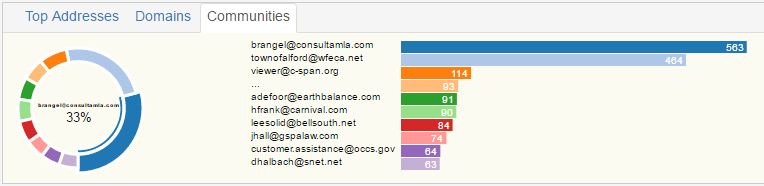
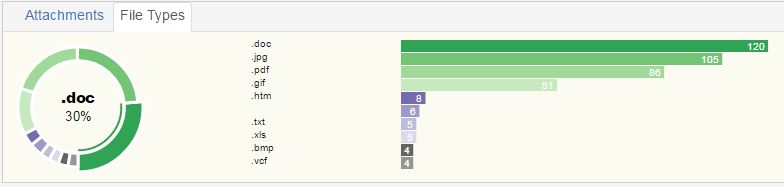
Attachments/File Types
this widget shows the distribution of attachment sent and received. File Types provides the top 10 types of attachements for the dataset selected.

Graph
The graph shows all of the communications between email addresses in the current view. It is built by directing the From to each To/Cc/Bcc. The thickness of the line shows more communications between the two nodes. As mentioned previously, the graph gets generated based off of email address selected, search result selected, or record in one of the analysis widgets.
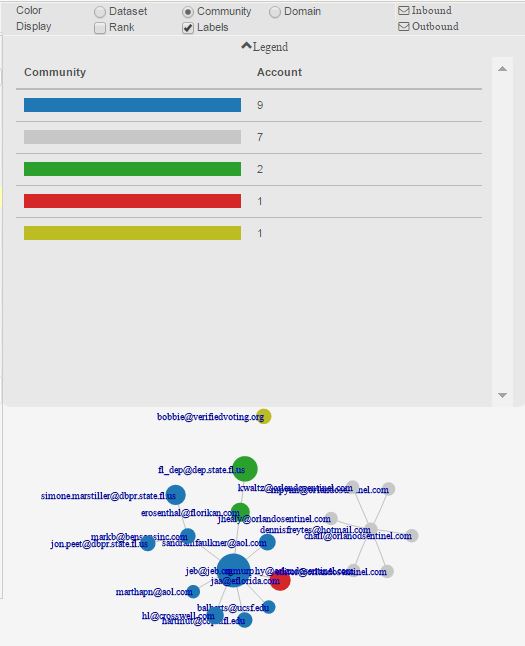
Graph Display
The graph can be colored by Domain or Community. The display can also show the Rank and Labels by toggling them on/off. Toggle the dropdown arrow for Legend to show a list of all of the visible Communities (or Domains) on the screen with the count for each along with the color. Hovering over one of the rows will highlight all of the emails for that Community (or Domain) in the graph. Hovering over a node will provide a count for Inbound and Outbound for that email address.
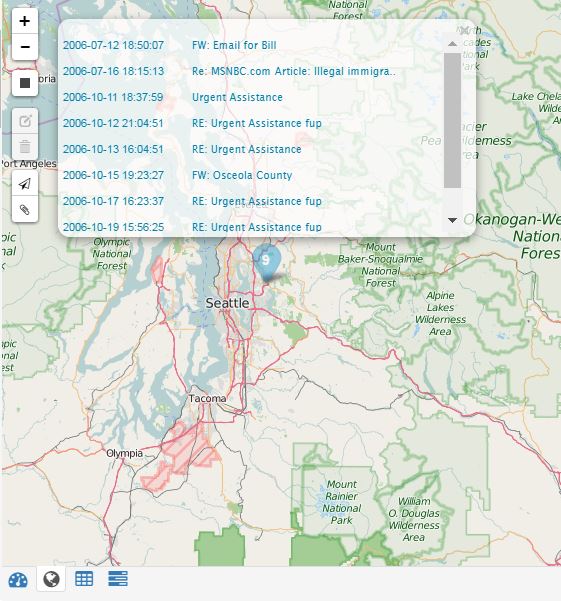
Geo Display
The geo display (map) shows all of the emails and attachments that have location data. The location from emails is a simple geo-lookup against the IP address and is just an approximate geographic location of the message sender. Attachments (in particular photos) may contain exif data which is more accurate.
The analyst can pan the map, zoom in, zoom out, and plot all the email that have location data. Selecting a location pin provides a list of emails associated with that location. The analyst can scroll through this list and display the email contents.
Extract
The Extract tab lists all the numeric data extracted during ingest. Currently, this is limited to phone numbers but in the future will include SSNs, DLs, credit card numbers and other well formed numeric entities.
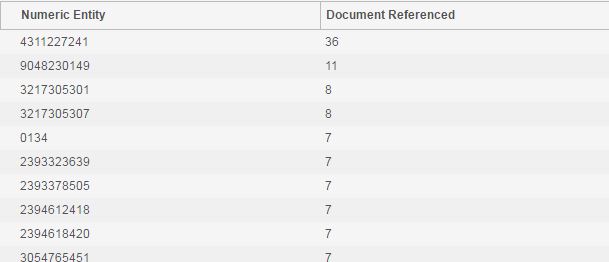
Email Table
The email table is populated by the same actions that populate the graph (selecting search term, email address, or record in analysis widget). This table contains a list of all the emails that matched the search criteria (including date range filter). The data can be sorted by each column. Selecting one of the rows displays the contents of that email in the Email View pane.
Selecting View Starred will list all the emails that have been marked as pertinent.
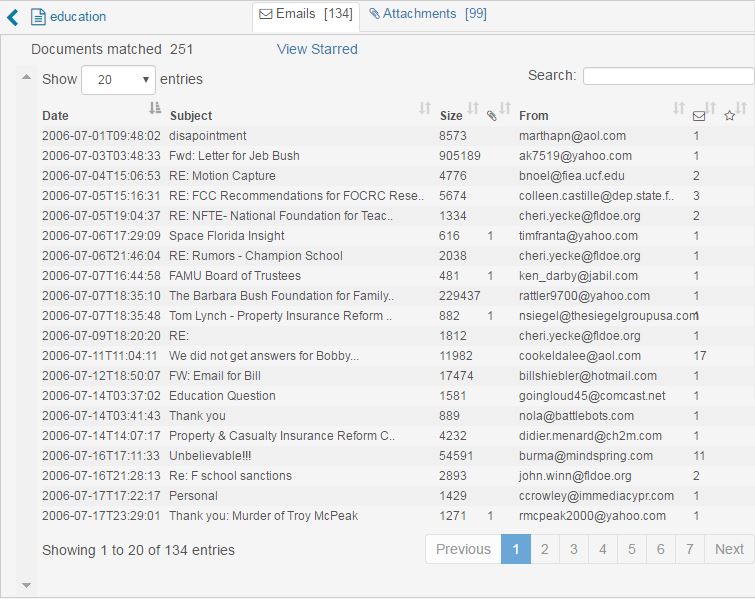
Attachments Table
The attachments table is populated by the same actions that populate the graph and email table (selecting search term, email address, or record in analysis widget). This table is populated with all of the attachments ever sent or received by that email address. Images are shown as previews and clicking on the title of the attachment will allow you to download it. You can also click the record to take you to that email.
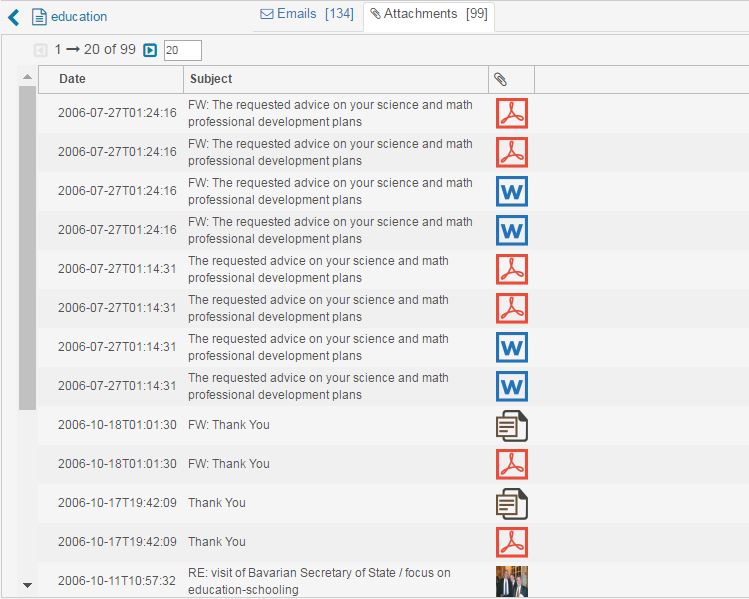
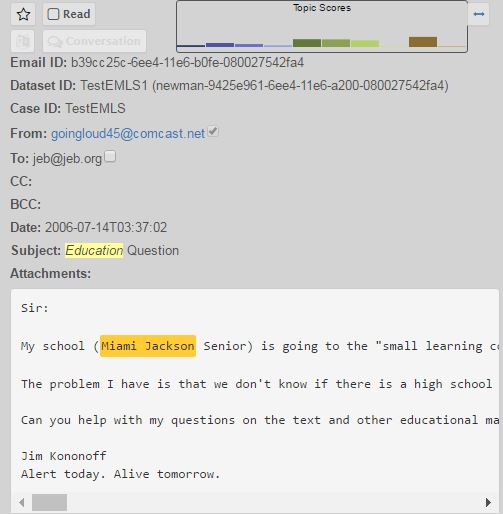
Email View
Entity Highlighting
Each email has entities extracted by MITIE highlighted in the body of the text. Clicking on one of the tagged entities will requery for all of the emails that contain that entity. The terms highlighted in yellow italics are not entities but the search term used. If a search term is also an entity then the entity highlighting takes precedence.
Mark Pertinent
At the top right of the Email View you can mark email pertinent (starred) by clicking the star. This action updates the Email List. These starred emails are the emails that can be exported. The list of marked emails can be viewed in Export.
Mark Read
Selecting checkbox for Read updates the Email List to grey out the record to indicate that the email has been read.
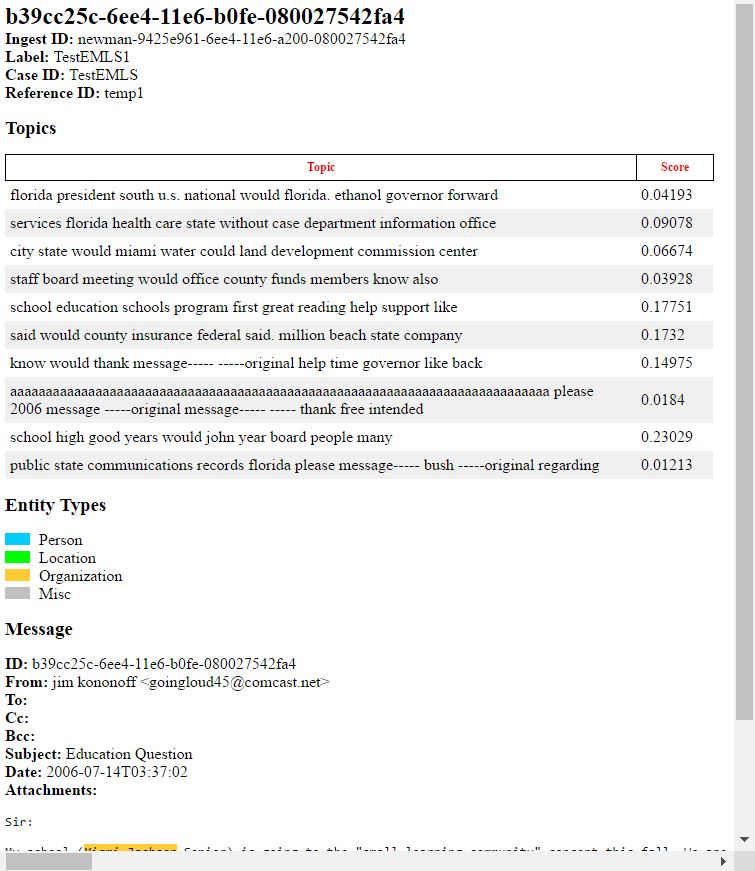
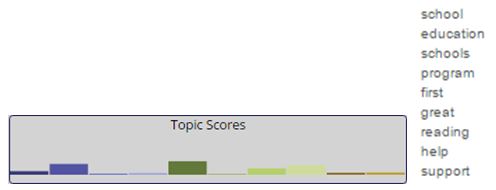
Topic Scores
At the top of each email view is a bar chart showing the topic scores from MIT-LL Topic Clustering each bar shows the percentage the current email scored in that topic. Mouse over each bar to see the top 10 terms that make up that topic. Clicking on one of the bars will re-query the dataset for that topic.
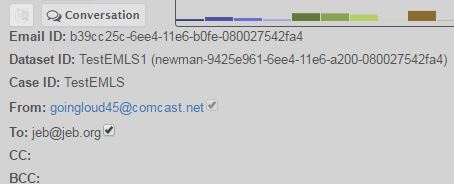
Email Conversation Intersection
For any email displayed, the analyst can get all the emails to a particular recipient. First select the recipient (from the To, Cc, or Bcc line) and then the Conversation button. This action updates the Email list to include only those emails from/to the selected addresses from that point forward or backward in time.
Email Translation
Email translation is provided for emails in another language using the  button. Currently, at this time only translations for Spanish is implemented.
button. Currently, at this time only translations for Spanish is implemented.
Export
Export creates an export.tar.gz file in the Download folder of all the emails that the user marked as pertinent (starred). The analyst can see a list of emails that have been marked by selecting View Starred in the Email View pane. The zipped file contains a separate folder for each email selected for export that contains a Chrome HTML Document with a summary of the email, a text information with the same information but without the graphics, the raw data in JSON file format and all the attachments.

Below is an example of the HTML summary.